當我們做完特徵工程,
判斷資料適合的模型後,
進行訓練的同時,要記得避免overfitting。
如Coursa上的課程「Generalization and ML Models」,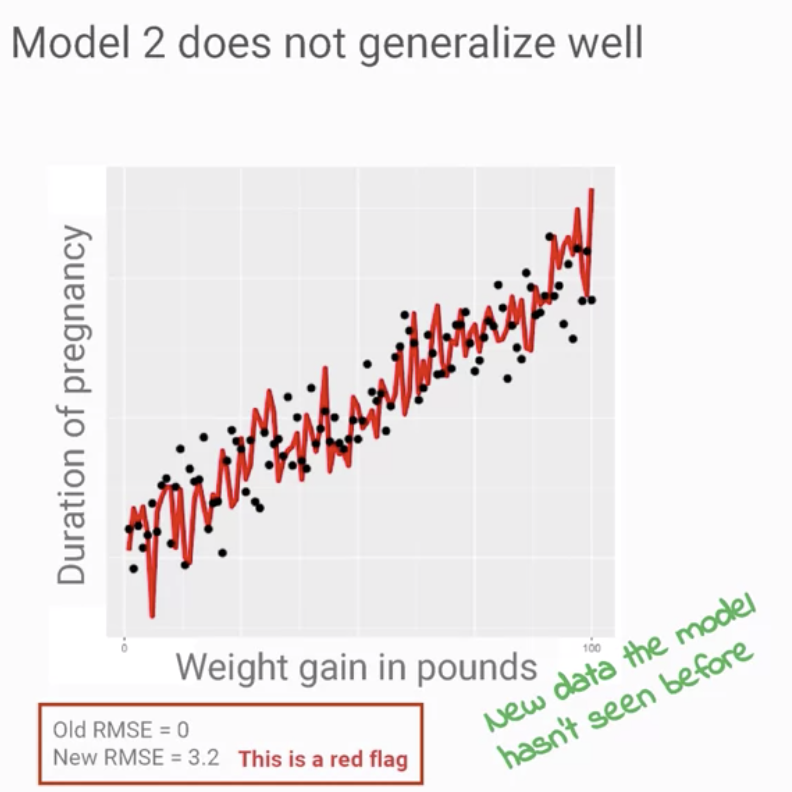
如上圖,RMSE從0躍升至3.2,這是一個巨大的問題,
表明該模型,在訓練數據集上「完全過分擬合」,
並且證明模型太脆弱或不能推廣到新數據。
三種情況圖形: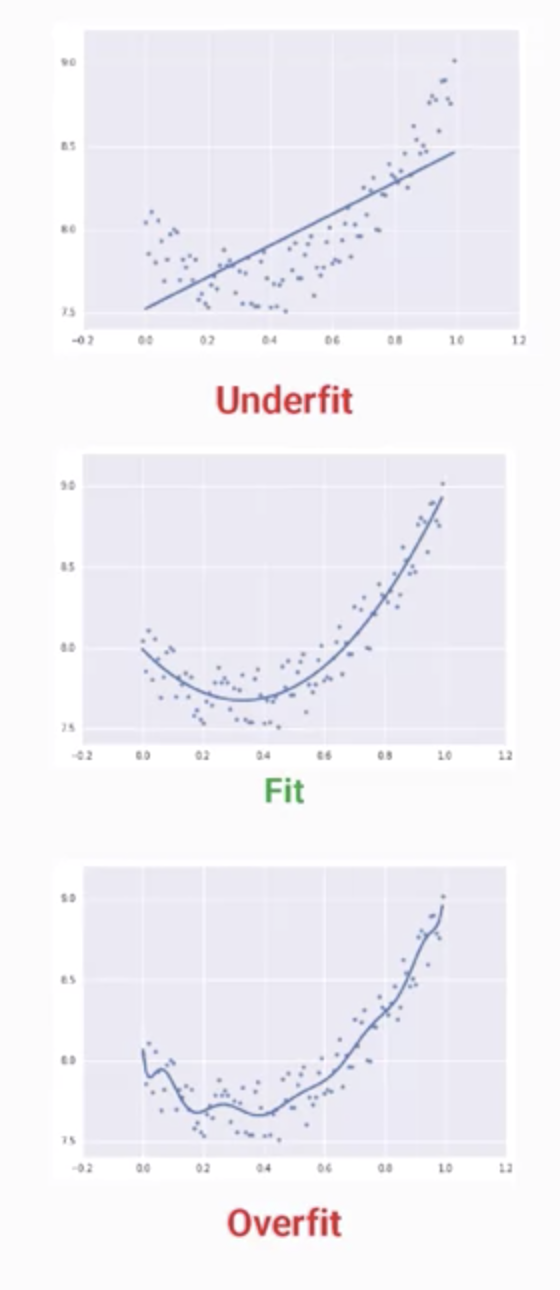
也可以再將資料分兩群驗證: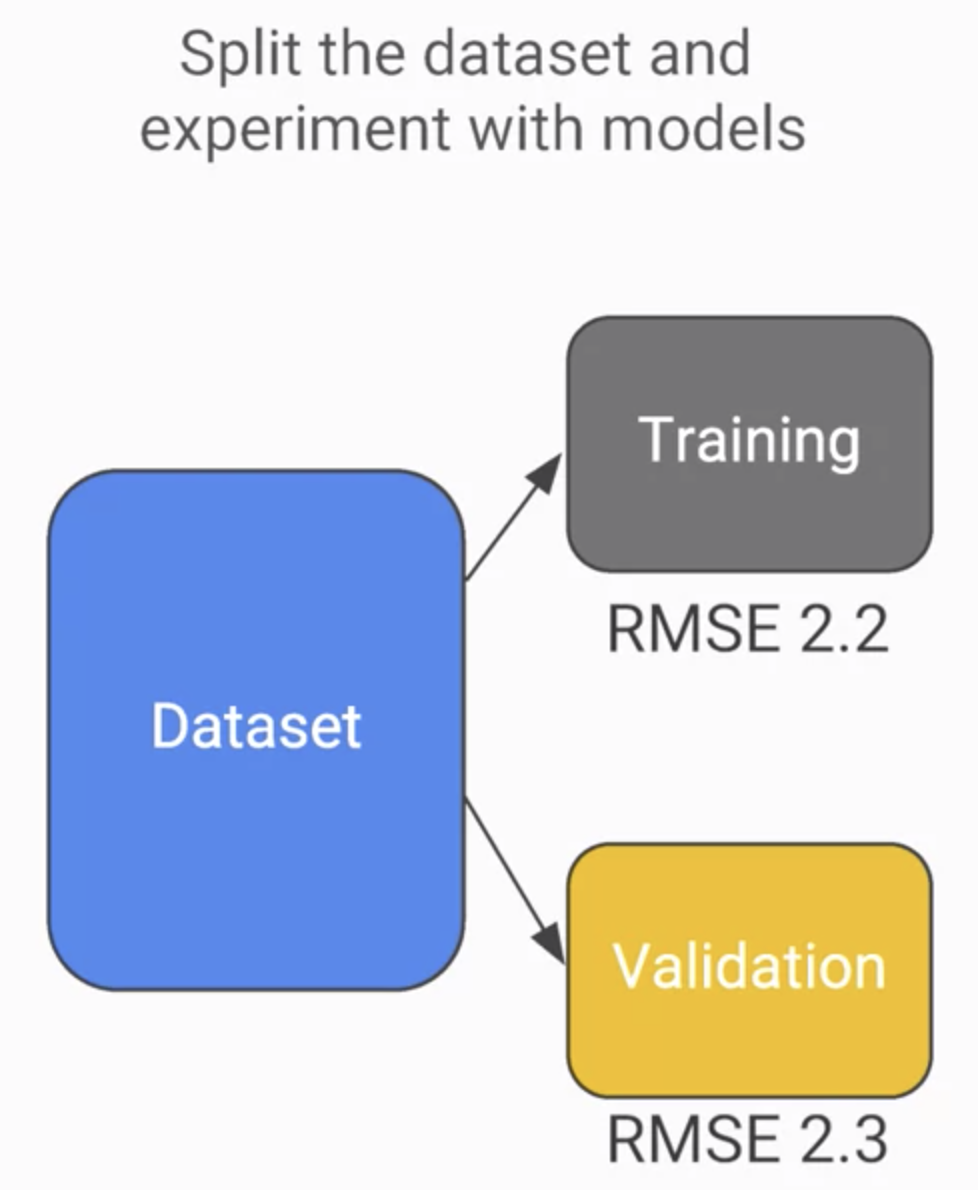
如Coursa上的課程「When to Stop Model Training」,
透過調整「超參數」來解決Overfit問題: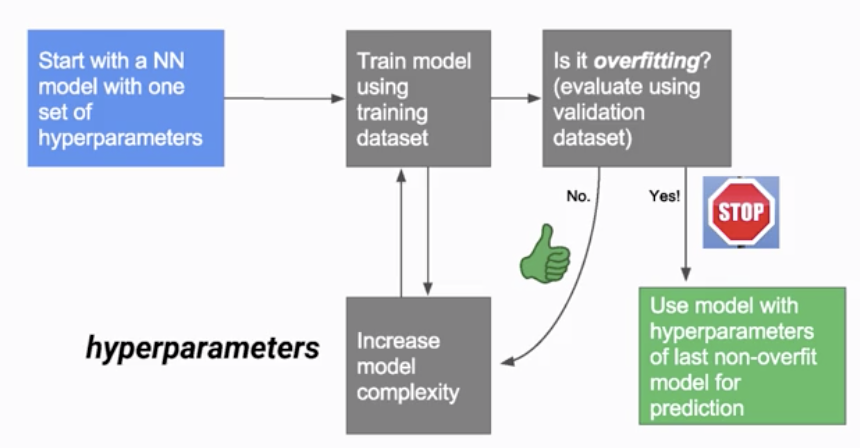
模型經過訓練和驗證後,在針對獨立的「測試」數據集進行一次。
若不幸最後的測試有錯誤,
除了再去重新蒐集資料外,
可以使用訓練和驗證資料進行「拆分技術」和「迭代次數」來改善,
得到多次的誤差值,進行「交叉驗證」。
以上,打完收工。


 iThome鐵人賽
iThome鐵人賽